
Are Pre-trained Convolutions Better than Pre-trained Transformers?
Published:
这是一篇来自ACL 2021的文章, 不同于以往Transformers征战CV无人可敌的情况, CV届传统一哥CNN现今也杀回NLP了领域. Google Research团队通过Convolutions替代Transformer进行预训练微调范式(pre-train-fine-tune paradigm), 在7个NLP任务中取得了不亚于Transformer的结果. 文章也对广大巨无霸预训练模型的成功得益与pre-training schemes或是model architectures提出了以下三个疑问, 让我们带着问题来阅读这篇文章.
- Are only Transformers able to capitalize on the benefits of pre-training? (只有Transformers才能发挥出预训练范式的优点吗?)
- If we use a different architectural inductive bias, would there also be a substantial gain unlocked by pre-training? (如果借助不同的模型架构作为归纳偏差进行预训练, 是否也会有显著收益?)
- Are pretrained convolutions better in particular scenarios? (在特定场景下,预训练卷积是否会比Transformers更好?)
Paper Title: Are Pre-trained Convolutions Better than Pre-trained Transformers?
Paper Source: ACL 2021
Paper Link: https://arxiv.org/abs/2105.03322
背景与预备知识
Convolution-based models的优缺点
Self-attention需要$O(L^2)$的空间复杂度, 需要消耗大量的GPU空间. 基于这个问题改进方案包括Weight Sharing Quantization / Mixed Precision, Knowledge Distillation等. 第一作者的另外一篇文章Efficient Transformers: A Survey中总结了相关模型与方法, 如图:

卷积是局部操作的,不依赖于位置编码作为模型的顺序信号.
卷积也有不少令人遗憾的缺点. 比如, 不能访问全局信息意味着没法建立多个序列之间的cross-attention
CNN in NLP
Pay less attention with light-weight &dynamic CNN - TheLongGoodbye的文章 - 知乎 https://zhuanlan.zhihu.com/p/60482693
[EMNLP 2014] Convolutional Neural Networks for Sentence Classification)
[ICLR 2016] Multi-Scale Context Aggregation by Dilated Convolutions
[ICML 2017] Convolutional sequence to sequence learning
[ICLR 2019 Oral] Pay less attention with lightweight and dynamic convolutions
TextCNN
最经典的将CNN应用于自然语言处理的方式, 使用多个卷积核对一个sequence进行表征学习生成feature maps, 使用max-over-time pooling将长度不同的feature maps映射到最后的representations中.

Standard Convolutions
标准应用于NLP的传统CNN如下图所示:
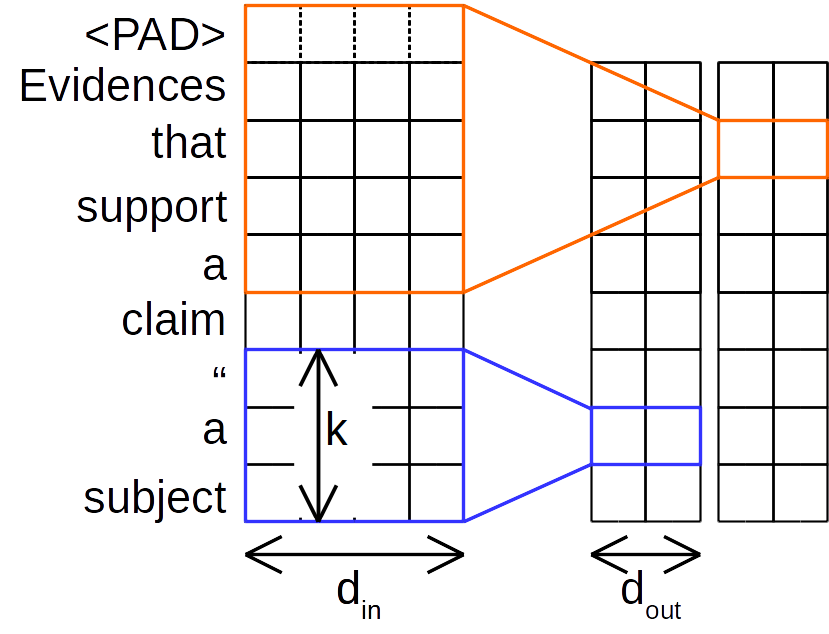
传统卷积方法同时考虑道和区域, 不同的卷积核有不同的尺寸,一个卷积核对输入序列的所有通道进行卷积计算. k是标准CNN的窗口大小, $d_{in}$和$d_{out}$分别是输入维度(如词嵌入维度)和隐状态维度, 下同.
Depthwise Convolutions (深度可分离卷积)
基于channel axis的卷积, 思想在于将通道和区域分开考虑, 即每个通道只有一个卷积核应用于此. 对于输入$X \in \mathbb{R}^{n \times d}$, Depthwise Convolution $D\left(X, W_{c,:}, i, c\right)$具有和输如$X$相同的维度, 其中position $i$, channel $c$ 上的值$O_{i, c}$计算方式为:
\[O_{i, c}=\operatorname{DepthwiseConv}\left(X, W_{c,:}, i, c\right)=\sum_{j=1}^{k} W_{c, j} \cdot X_{\left(i+j-\left\lceil\frac{k+1}{2}\right\rceil\right), c}\]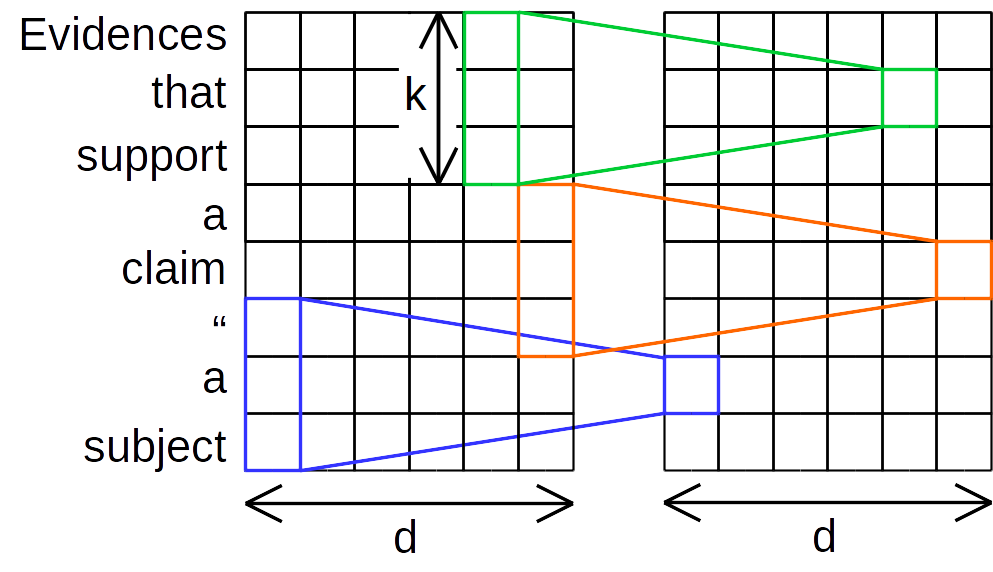 如上图所示, 单个通道只与一个卷积核有交互关系, 例如原始序列的第一个通道只与蓝色的卷积核相关, 从而得到输出序列中的第一个维度. 这样一来,卷积的计算量将从标准卷积的$O(k \times d^2)$降低至深度可分离卷积的$O(k \times d)$.
如上图所示, 单个通道只与一个卷积核有交互关系, 例如原始序列的第一个通道只与蓝色的卷积核相关, 从而得到输出序列中的第一个维度. 这样一来,卷积的计算量将从标准卷积的$O(k \times d^2)$降低至深度可分离卷积的$O(k \times d)$.
Lightweight Convolutions (轻量化卷积)
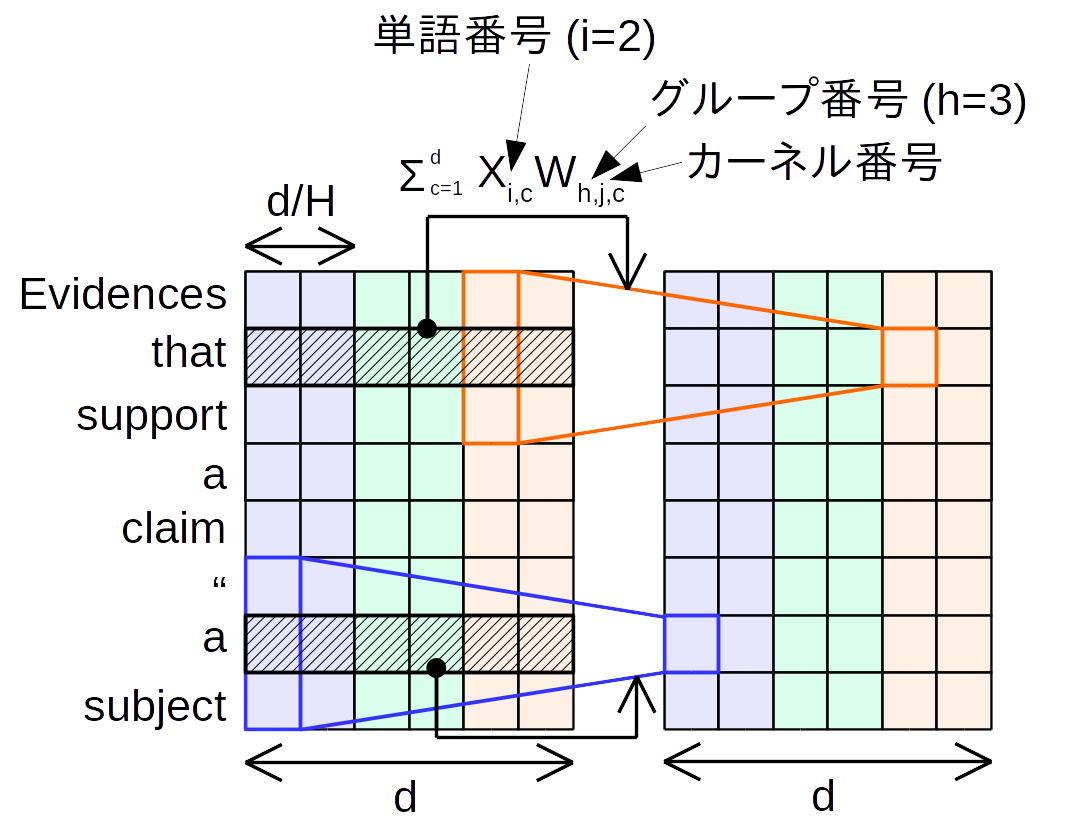
借助softmax-normalized kernels来实现, 关键思想是学习特定位置的核来执行轻量级卷积. 同时轻量化卷积在深度卷积的卷积核的基础上采取参数共享机制,即将通道分为 $H$个,在分割的子通道上实现参数共享:
\[\operatorname{LightConv}\left(X, W_{\left\lceil\frac{c H}{d}\right],:} i, c\right)=\text { DepthwiseConv }\left(X, \operatorname{softmax}\left(W_{\left\lceil\frac{c H}{d}\right],:}\right), i, c\right)\]其中$\hat{c}=\frac{c H}{d}$, 即每$\frac{d}{H}$个output channels间参数是共享的. 当$H=1$时等价于所有channels的参数是共享的, 如下图所示:
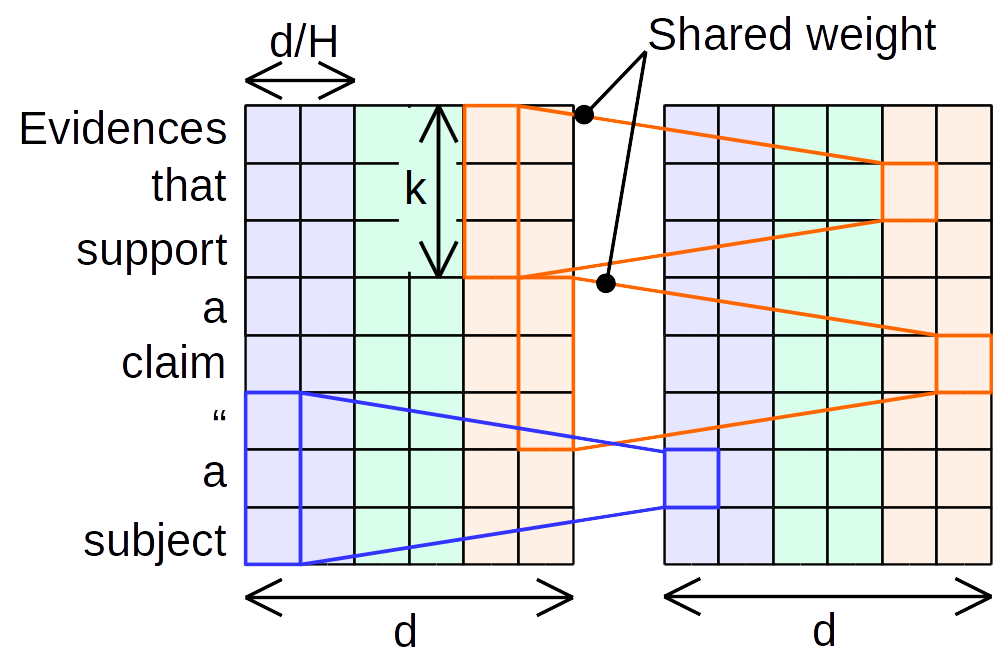
在卷积的计算量上轻量化卷积则更进一步, 将从深度可分离卷积的 $O(k \times d)$ 降低 $O(k \times H)$.
在此基础上, LightConv Block需要额外引入GLU(线性门控单元), 并串联两层linear projection, 整体架构如下:
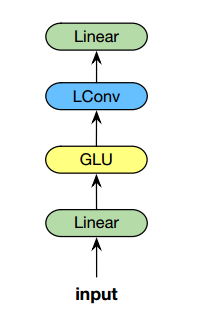
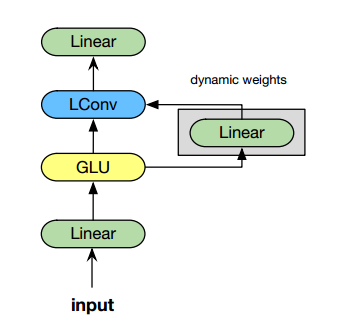
Dynamic Convolutions (动态卷积)
Dynamic Convolutions是Lightweight Convolutions的一种新形式, 在每一个时间步预测卷积的权重. 这样通过$f(\cdot)$学习每个当前位置上的权重而不是固定的, 计算方式为
\[\text { DynamicConv }(X, i, c)=\operatorname{LightConv}\left(X, f\left(X_{i}\right)_{h,:}, i, c\right)\]其中$ f(\cdot): \mathbb{R}^{d} \rightarrow \mathbb{R}^{H \times k}$是一个线性变换用来学习position dependent kernel, 原文用一个简单的线性映射来实现. 可以看到哪怕加入了一个额外的可学习参数$ f(\cdot)$, Dynamic Convolutions复杂度仍与序列长度$L$保持线性相关.
与LightConv Block类似, DynamicConv Block的结构如下:
Dilated Convolutions (空洞卷积):
Dilated/Atrous Convolution 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)
作者:刘诗昆 链接:https://www.zhihu.com/question/54149221/answer/323880412 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Convolution VS Self-attention
重新回顾一下Attention, 同样地我们有输入$X \in \mathbb{R}^{n \times d}$, 通过$W_Q, W_K, W_V$线性映射得到key, query, and value representations. 还可以通过定义多个Head来实现multi-head机制, 每个头部可以学习不同的注意力权重, 关注不同的位置. 同时通过对于Query和Key的点积结果的归一化来表示attention score, 同时辅助以sclae机制避免其值过于尖锐, 最后将其作为权重计算Value的weighted sum:
\[\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V\]
我们不难看出, 动态卷积(GLU + Convolutions+ Lienar) 实际上是对于query-key-value based self-attention机制的一种模拟, 很好地体现了attention map 归一化、multi-head,以及线性映射. 下面这个表格大致展示了相应的模拟关系(只是粗浅对比, 深度学习的东西谁又能说得准呢~)
| Dynamic Convolutions | Self-attention |
|---|---|
| input projection | query-key-value projection |
| softmax-normalized kernels | attention map softmax |
| multi-channels | multi-head |
| output projection | attention projection |
预训练与Transformers
使用基于self-attention生成contextual representations 模型架构结合一个巧妙的预训练目标, 在大量未标注的预料下进行self-supervised learning似乎成为了巨无霸深度学习模型的标配, 也取得了广泛成功, 例如BERT, XLNet, RoBERTa, GPT family, BART, T5, etc.
但是这样的训练模式选择的backbone并不是Transformers, 比如基于LSTM的ELMo和CoVE. 同时训练微调范式(pre-train-fine-tune paradigm)也不是NLP领域的专属, CNN backbone在ImageNet上的预训练在CV领域也获得了巨大的成功.
这就是Question 1,2,3的背景, 本文想通过实验调研预训练与Transformers解耦后的对比效果, 而文章通过预训练CNN来实现这一设想.
模型架构
预训练目标
与T5类似, 本文构造了一种基于Span(多个tokens)预测的预训练目标: 将input sentence中的部分spans随机mask(同特殊token [mask]替换)并生成被mask的span, 例如:
Inputs: The happy cat sat [mask]
Outputs: on the mat
基于卷积的Seq2Seq架构
提出了一个预训练的卷积Seq2Seq模型,用卷积块替代了Transformer架构中的multi-headed selfattention机制, 其中每个卷积块可以表示如下:
\[\begin{equation} \begin{aligned} &X^{1}=W^{I} X \odot \operatorname{sigmoid}\left(W^{S} X\right) \\ &X^{2}=\operatorname{ConvBlock}\left(X^{2}\right) \\ &X^{3}=W^{O}\left(X^{2}\right) \end{aligned} \end{equation}\]与Transformer类似的, 本文提出的Convolutional Seq2Seq在每个Conv层的上下用Layer normalization和residual connectors包裹, 并串联Feed Forward Network, 即:
\[\begin{equation} \begin{aligned} X_{A} &=\operatorname{LayerNorm}(\operatorname{Conv}(X))+X, \\ X_{B} &=\operatorname{LayerNorm}\left(\operatorname{FFN}\left(X_{A}\right)+X_{A}\right. \end{aligned} \end{equation}\]从原生Transformer的架构中我们可以参透到, Feed Forward Network在模型中其实扮演了重要的成分, 也有多篇相关文章指出这一点. 从参数量上规模上来看, Feed Forward Network也不低于self-attention weights. 文章提出的Convolutional Seq2Seq Architecture可以简单地理解为将Transformer中的self-attention block替换为Convolutional Block.
所以下文实验中的Convolution vs Transformer的对比, 看上去舞台很大对抗很激烈, 观点很新颖, 其实有点名过其实, 实际上可以看成是Convolution-based Transformer与Attention-based Transformer的对比
优化目标
基于token-wise cross-entropy loss可以得到模型最后的优化目标, 即对比input sequence和predicted sequence中每一个time step $t$的在不同class $i$下的结果:
\[L=\sum_{t=1}^{L} \sum_{i=1}^{n} \log \left(\pi_{i}^{t}\right)+\left(1-y_{i}^{t}\right) \log \left(1-\pi_{i}^{t}\right)\]实验与分析
实验设置
在八种不同NLP任务下进行实验, 包括
- Toxicity Detection (攻击性言论检测任务): CIVIL COMMENTS, WIKI TOXIC SUBTYPES
- Sentiment Classification (情感分类任务): IMDb review, Stanford Sentiment Treebank (SST-2), Twitter Sentiment140(S140)
- News Classification (新闻分类任务): AGNews
- Question Classification (问题分类任务): TREC
- Semantic Parsing / Compositional Generalization: COGS
具体数据集统计信息如下:

在实验过程中, seq2seq架构中的ConvBlock采用了多种卷积机制进行试验, 包括Lightweight convolutions, dynamic convolutions and dilated convolutions. 设置细节见原文. 同时对于both raw (no pre-training) and pre-train-finetune paradigms进行了对比试验, 预训练语料来自于Colossal Cleaned CommonCrawl Corpus (C4), 最大掩盖span数量为3, 掩盖比例为15%, 层数、序列长度等参数与 BART-base 保持了一致.
实验结果

在多个下游任务上进行实验后可以看到, 在一些任务上性能追平了基于Transformers(T5)
以上实验结果表明:
在7个数据集中(COGS没结果???)未经预训练的卷积要优于未经预训练的Transformers
- 6/7项任务(除了IMDb),经过预训练的卷积优于预训练的Transformers
- 预训练微调范式(pre-train-fine-tune paradigm)同样可以帮助convolutions-based model提升模型性能, 并不是只有transformer-based model可以从中受益
- 在预训练的卷积模型中, dilated convolutions $ \approx$ dynamic convolutions $>$ lightweight convolutions
- 模型在raw (non-pre-training)和pre-training训练下在下游任务的性能表现并没有直接关系. 告诫我们预训练微调范式固然可以结合不同模型架构使用, 但是还需要注意不同模型架构在预训练下的行为可能不同.
讨论与展望
交叉注意力缺失
由于卷积的结构特性, 其天然在交叉注意力归纳偏差(cross-attention inductive bias)的处理上有一定的缺失, 所以使用pre-trained convolutions处理自然语言推理(NLI)这类包含多序列语义交互的任务会显然易见地比较棘手. 作者在SQuAD以及MultiNLI这两个任务上对比了convolutions以及transformer进行了实验, 证明了这一猜测, 即premise和hypothesis, question和context缺少了cross-attention所带来的交互. 但是如果给Convolution-based encoder中加上一层简单的attention, 就可以达到与Transformer近似的结果.
| F1 on SQuAD | Accuracy on MultiNLI | |
|---|---|---|
| Convolutions | 70% | 75% |
| Transformer | 90% | 84% |
| Convolutions + one layer attention | 83% | 83% |
卷积可以更快更好地应对长序列
在不同长度的预训练任务中, 卷积始终表现出了更快的运行速度, 且面对长序列场景Convolutions具有更好的可拓展性.

卷积具有高效计算性
FLOPS数量变化的对比上, 卷积也相对于Transformers表现出了优势—在所有序列长度上,卷积都更高效.
